
Удивительно, что в наше время лучший способ поиска новой одежды — щелкнуть несколько флажков и прокрутить бесконечные картинки. Почему вы не можете найти «зеленое платье с рисунком в виде совка» и увидеть его? Glisten Это новый стартап, позволяющий использовать компьютерное зрение, чтобы понять и перечислить самые важные аспекты одежды на любой фотоснимки.
Теперь вы можете думать, что это уже существует. В некотором смысле, это так, но не так, чтобы это было полезно. Соучредитель Алиса Денг столкнулась с этим, когда работала над собственным проектом по поиску моды во время учебы в MIT.
«Я откладывал покупки в интернете, и я искал рубашку с V-образным вырезом, и только 2 вещи подошли. Но когда я пролистал, их было около 20, — сказала она. «Я понял, что вещи были помечены очень противоречивыми способами — и если данные настолько велики, когда потребители видят их, это, вероятно, еще хуже в бэкэнде».
Как выяснилось, системы компьютерного зрения были обучены идентифицировать, действительно достаточно эффективно, особенности всех видов изображений, от идентификации пород собак до распознавания выражений лица. Когда дело доходит до моды, они делают то же самое: смотрят на изображение и генерируют список функций с соответствующими уровнями достоверности.
Таким образом, для данного изображения, он будет производить своего рода список тегов, например так:

Как вы можете себе представить, это на самом деле довольно полезно. Но это также оставляет желать лучшего. Система не совсем понимает, что на самом деле означают «бордовый» и «рукав», за исключением того, что они присутствуют на этом изображении. Если бы вы спросили систему, какого цвета рубашка, она была бы озадачена, если бы вы вручную не отсортировали список и не сказали, что эти две вещи — это цвета, это стили, это вариации стилей и так далее.
Это не сложно сделать с одним изображением, но у розничного продавца одежды может быть тысячи продуктов, каждый с дюжиной фотографий, а новые выходят еженедельно. Хотите стать стажером, назначенным для копирования и вставки тегов в отсортированные поля? Нет, и никто другой. Это проблема, которую решает Glisten, делая движок компьютерного зрения значительно более контекстно-зависимым, а его результаты — гораздо более полезными.
Вот то же изображение, которое может обрабатывать система Glisten:
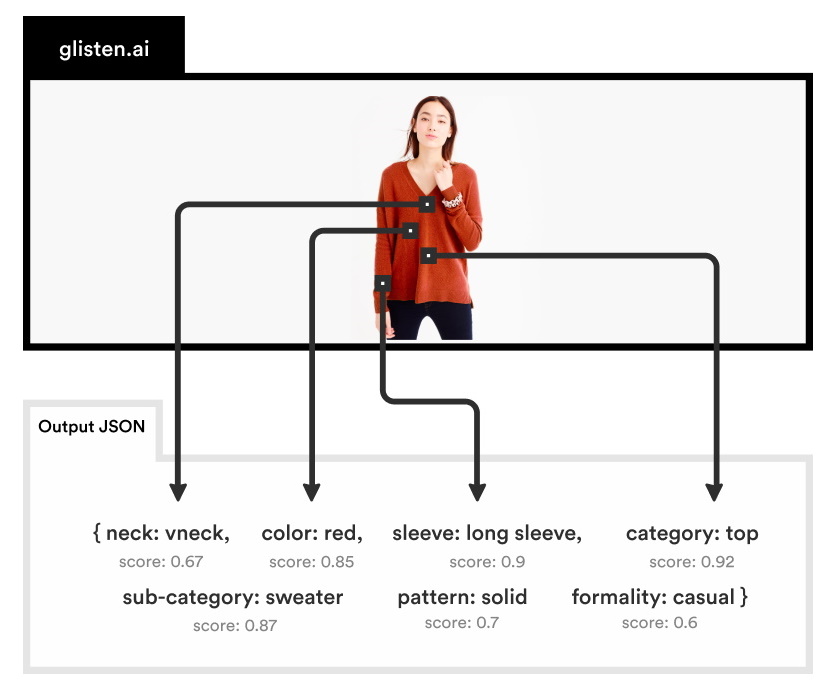 Лучше, верно?
Лучше, верно?
«Наш ответ API будет на самом деле, декольте это, цвет этошаблон это«Дэн сказал.
Такого рода структурированные данные могут быть гораздо проще подключены к базе данных и надежно опрошены. Пользователи (не обязательно потребители, как объясняет Дэн позже) могут смешивать и сопоставлять, зная, что когда они говорят «длинные рукава», система на самом деле смотрит на рукава одежды и определили, что они длинная,
Система была обучена работе с растущей библиотекой из примерно 11 миллионов изображений продуктов и соответствующих описаний, которые система анализирует с использованием обработки на естественном языке, чтобы выяснить, что относится к чему. Это дает важные контекстуальные подсказки, которые мешают модели думать, что «формальный» — это цвет, или «милый» — это повод. Но вы были бы правы, считая, что это не так просто, как просто подключить данные и позволить сети понять это.
Вот своего рода идеализированная версия того, как это выглядит:
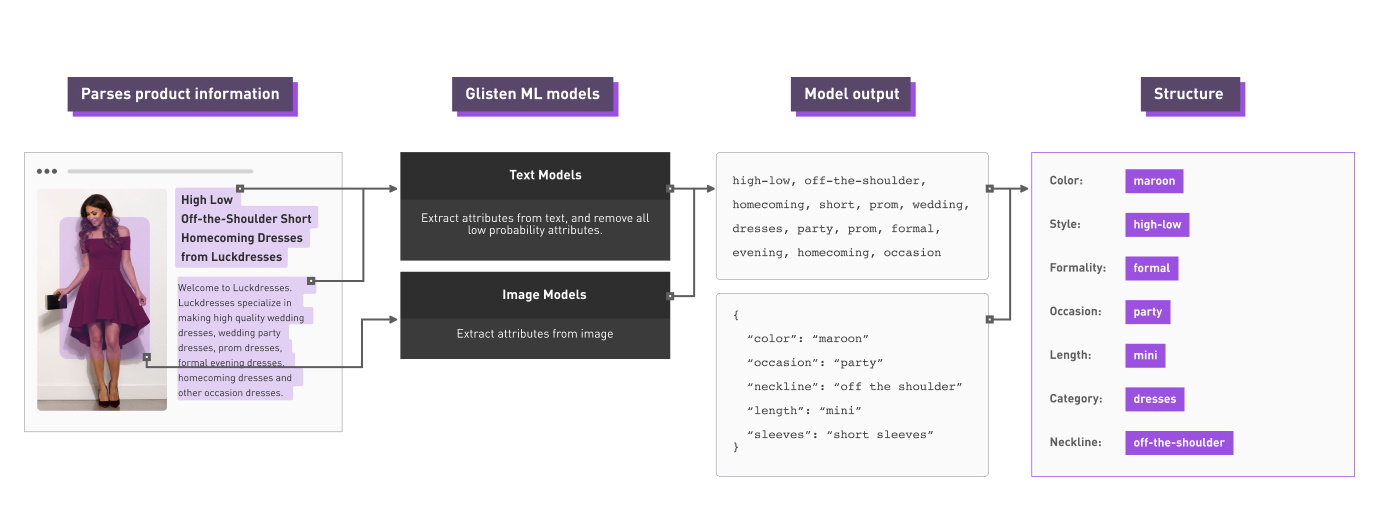
«В моде много неясностей, и это определенно проблема», — признал Дэн, но далеко не непреодолимый. «Когда мы предоставляем результаты для наших клиентов, мы как бы присваиваем каждому атрибуту оценку. Так что, если это будет неоднозначно, будь то шейка экипажа или шейка, если алгоритм работает правильно, то это будет иметь большой вес для обеих сторон. Если вы не уверены, это даст более низкий показатель достоверности. Наши модели обучены на совокупности того, как люди маркируют вещи, так что вы получите среднее значение того, что люди думают ».
Хотя покупатели, скорее всего, со временем увидят преимущества технологии Glisten, компания обнаружила, что ее клиенты фактически находятся в двух шагах от торговой точки.
«Со временем мы поняли, что правильный клиент — это тот клиент, который чувствует боль в том, чтобы иметь грязные и ненадежные данные о продукте», — пояснил Дэн. «В основном это технологические компании, которые работают с ритейлерами. Нашим первым клиентом была компания по оптимизации цен, а другой — компания цифрового маркетинга. Это довольно далеко от того, что мы думали, приложения будут ».
Это имеет смысл, если вы думаете об этом. Чем больше вы знаете о продукте, тем больше данных вы должны соотносить с поведением потребителей, тенденциями и тому подобным. Знание летних платьев возвращается, но лучше знать сине-зеленые цветочные узоры с рукавами 3/4.

Glisten соучредители Сара Вудер (слева) и Алиса Денг.
Модель изначально нацелена на моду и одежду в целом, но ее можно адаптировать к другим категориям без необходимости заново изобретать колесо — те же алгоритмы могут найти определяющие характеристики автомобилей, косметических товаров и так далее.
Конкуренция — это, в основном, команды внутренних тегов (обзор, созданный нами вручную, который никто из нас не хотел бы), и универсальные алгоритмы компьютерного зрения, которые не производят структурированные данные, которые делает Glisten.
Даже впереди Y Combinator's Демонстрационный день на следующей неделе компания уже видит 5 цифр ежемесячного повторяющегося дохода, при этом процесс продаж ограничивается индивидуальным взаимодействием с людьми, которые, по их мнению, сочтут это полезным. «За последние несколько недель количество продаж было сумасшедшим», — сказал Дэн.
Вскоре Glisten может привести в действие многие поисковые системы в Интернете, хотя в идеале вы даже не заметите — если повезет, вы просто найдете то, что ищете, гораздо проще.